Apache Tika 개요
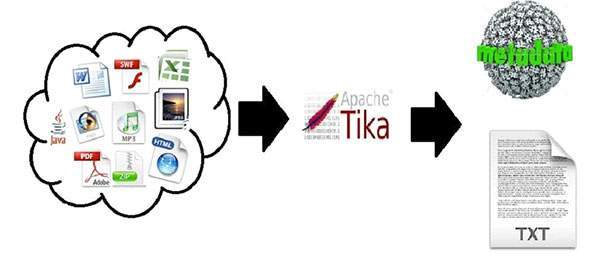
- 아파치 Tika는 문서 타입 검출 및 다양한 파일 형식에서 컨텐츠를 추출하는 기능을 제공하는 라이브러리이다.
- 내부적으로, Tika는 현존하는 다양한 문서 파서(parse)들과 문서 타입 검출 및 데이터를 추출하는 기법들을 활용하고 있다.
- Tika를 활용해 광범위한(universal) 타입 검출기 및 스프레드 시트, 텍스트 문서, 이미지, PDF 및 멀티미디어 입력 포맷 등의 다양한 형식의 문서에서 구조화된 텍스트와 메타 데이터를 추출할 수 있는 컨텐츠 추출기를 제작할 수 있다.
- Tika는 다양한 파일 형식을 파싱(parsing)할 수 있는 단일 범용 API를 제공한다. 각각의 문서 타입을 처리하기 위해 83가지 전문화된 파서(parser) 라이브러리를 사용한다.
- 이러한 파서 라이브리들은 Parser 인터페이스라는 단일 인터페이스 내에 캡슐화 되어 있다.
왜 Tika를 써야 하는가?
filext.com 에 따르면 1,5000 에서 51000 가지의 컨텐츠 타입이 존재하는 것으로 추정되며, 이러한 수치는 날마다 증가하고 있다. 데이터 텍스트 문서, 엑셀 스프레드 시트, PDF, 이미지, 멀티미디어 등 다양한 형식으로 저장 되어지고 있다. 따라서, 검색엔진과 컨텐츠 관리 시스템 등의 어플리케이션은 다양한 문서 타입에서 손쉽게 데이터를 추출할 수 있는 기능을 필요로 한다. Apache Tika는 다양한 파일 형식에서 데이터를 찾아내고 추출하는 범용적인 API를 제공하기 위해 만들어 졌다.
Apache Tika 어플리케이션들
다양한 어플리케이션들을 Tika를 이용해 만들 수 있다.
검색 엔진(Search Engine)
Tika는 검색 엔진이 디지털 문서들의 텍스트 컨텐츠를 색인하는데 사용된다.
문서 분석(Document Analysis)
인공 지능 분야에서는 문서를 자동으로 의미론(semantic)적으로 분석하고, 모든 유형의 데이터를 추출하는 도구들이 있다.
이러한 어플리케이션에서는 문서에서 추출된 컨텐츠에 포함된 중요한 용어들을 기반으로 문서들이 저절로 분류된다.
이러한 도구들에서 Tica는 문서를 분석하기 위해 컨텐츠를 추출하는 기능을 수행한다.
디지털 자산 관리 (Digital Asset Management)
어떤 기관들은 사진, e-book, 음악, 설계도, 그림, 비디오 등의 디지털 자산을 관리하는 특별한 어플리케이션을 사용하는데 이를 디지털 자산 관리 시스템이라고 부른다.
이러한 어플리케이션에서 문서의 타입 검출 기능과 다양한 문서들을 분류하기 위한 메타 데이터 추출기를 사용한다.
컨텐츠 분석(Contents Analysis)
Amazon 같은 웹 사이트들은 고객들의 관심사에 기반한 맞춤형 컨텐츠를 제공한다. 이렇게 하기 위해, 머신 러닝(machine learning) 기술을 적용하거나, Facebook 같은 소셜 미디어 네트워크의 도움을 받아 사용자의 기호(interest)와 좋아하는 것들에 대한 정보를 수집한다. 이렇게 수집된 정보들은 HTML와 그외의 다양한 형식으로 존재하며, 컨텐츠 타입 검출 및 추출 과정을 거치게 된다.
문서의 컨텐츠를 분석하기 위해 UIMA 및 Mahout 같은 머신 러닝 기술이 활용된다. 이러한 기술들은 문서의 데이터를 클러스터링하고 분석하는데 쓰인다.
Apache Mahout는 Apache Hadoop 위에서 Machine Learning 알고리즘을 제공하는 프레임워크이다. Mahout은 클러스터링 및 필터링 기술을 제공하며, 프로그래머들은 자신만의 고유한 ML 알고리즘을 이용해 다양한 텍스트와 메타데이터 조합을 이용해 추천 정보를 생산할 수 있게 된다. 최근 버전의 Mahout은 ML을 위한 입력 데이터를 생성하기 위해 Tika를 이용하고 있다.
Apache UIMA 는 다양한 프로그래밍 언어를 분석하고 처리하고, UIMA 어노테이션(annotations)을 생성한다. 내부적으로 Tika Annotator를 문서의 텍스트와 메타 데이터를 추출하기 위해 사용한다.
출처 : http://www.tutorialspoint.com/tika/tika_quick_guide.htm
